
L’application ChatGPT réussi à réaliser des tâches qui, lorsqu’elle sont faites par des humains, nécessitent une compréhension en profondeur, non seulement des énoncés décrivant les objectifs à atteindre, mais aussi de certains concepts et principes à utiliser pour atteindre ces objectifs.
Voici un exemple :

On peut admettre que résoudre ce problème ne nécessite pas de comprendre en profondeur ce qu’est une personne, que Mélissandre et Isabeau sont des prénoms, ni ce qu’est un panier garni. Par contre, pour résoudre un tel problème, une personne humaine doit comprendre les concept de somme et de produit et être capable de faire un raisonnement arithmétique pour exprimer et résoudre, ne serait-ce que par tâtonnement, une équation simple.
Ou alors… une personne humaine ayant mémorisé une recette pour résoudre ce type de problème sans comprendre ce qu’elle fait pourrait reconnaitre le type dénoncé, en identifier les variables et paramètres, et les mettre en correspondance les variables et paramètres de la recette. Mais cela reste une tâche complexe qui va très au delà d’une simple reproduction ou imitation.
Pourtant, nombre de voix, dans les média, minimisent les capacités de ChatGPT.
ChatGPT est un perroquet qui répond de manière aléatoire.
Dans un entretien avec Jean-Gabriel Ganascia (chercheur en intelligence artificielle au sein du laboratoire de recherche en informatique de Sorbonne Université) publié dans le journal « Le Point » en janvier 2023.
Il fabrique des textes mot après mot de telle manière que chacun d’entre eux soit suivi des occurrences statistiquement dominantes dans la gigantesque base de données identifiée par ses concepteurs (qui représente plus de 750 000 fois le volume de la Bible)
Philippe Meirieu, professeur honoraire en sciences de l’éducation, dans une tribune publiée le 27 mars 2023 dans le journal « Le Monde ».
Quand on lui fait une demande, on lui donne des séquences de mots en entrée et lui il cherche juste à lui associer les mots qui correspondent les plus probablement mais sans en comprendre le sens. Ça reste une mécanique de réponse très basique.
Vidéo de mars 2023 sur la chaîne Youtube Defakator Vite Fait. « Vite fait : comment fonctionne ChatGPT ?«
Un algorithme extraordinairement complexe et qui est extraordinairement efficace pour réaliser une tâche extraordinairement dérisoire, au fond : prédire le prochain mot d’un texte. Ou plus exactement, à partir d’une séquence de mots, donner une distribution de probabilité de ce que pourrait être le prochain mot. Voilà, c’est tout.
Monsieur Phi, philosophe, vulgarisateur scientifique, dans une vidéo de janvier 2023 intitulée « De quoi ChatGPT est-il vraiment capable ? » sur sa chaîne de Youtube.
Peut-on mettre ces affirmations en cohérence avec l’exemple suivant :
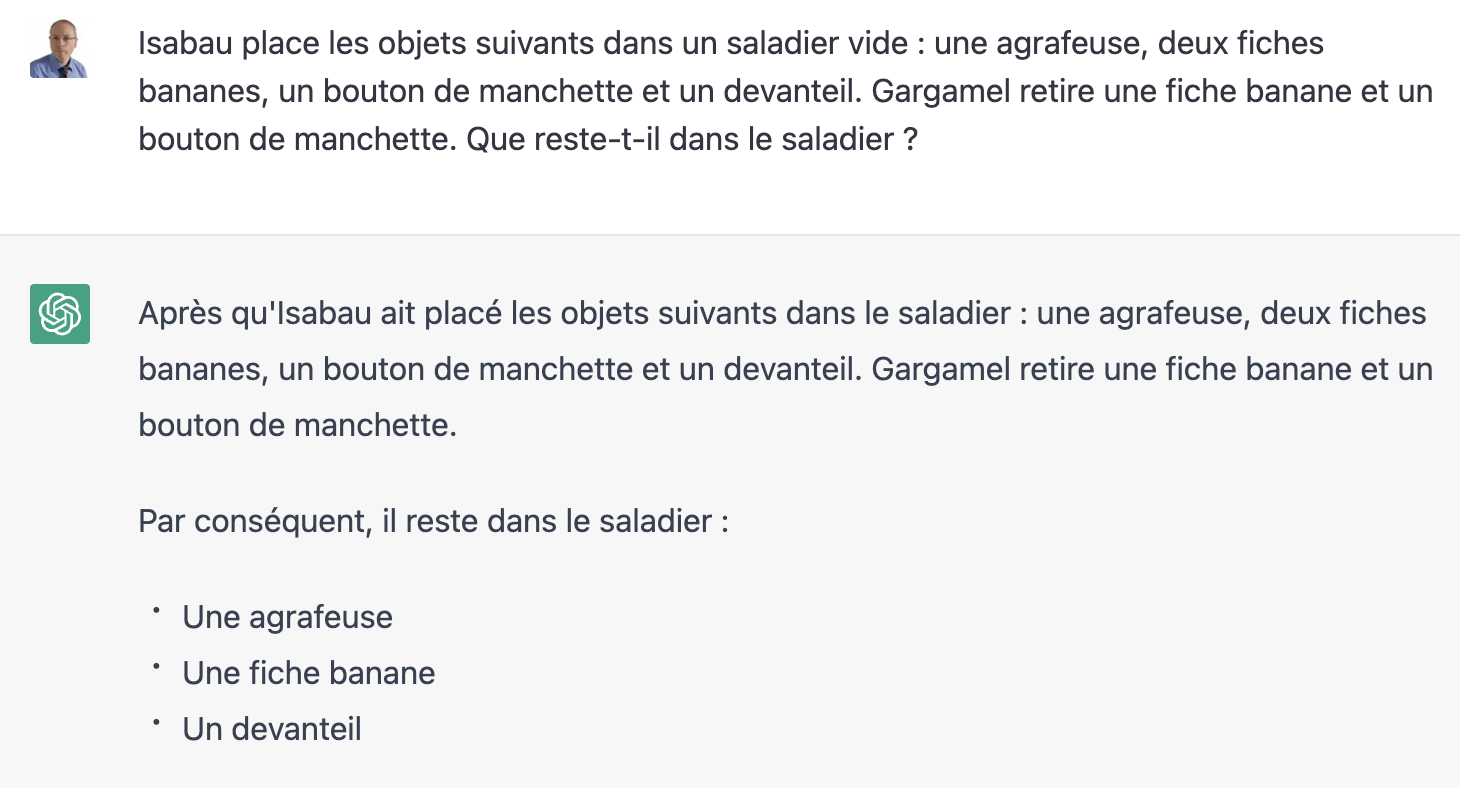
Le mot « devanteil » désigne un tablier en patois Bourguignon. Il est plus qu’improbable que ce mot figure à proximité des mots « fiche banane » et « bouton de manchettes » dans le corpus d’apprentissage de ChatGPT. Et en cas de doute, on peut utiliser d’autres noms d’objet inusités, ou même complètement inventés, et constater que le Truc donne une réponse correcte à la question posée.
Il est clair que la réponse obtenue ne peut être construite par une suite de mots ayant des occurrences statistiquement dominantes dans un corpus d’apprentissage plausible.
La quatrième citation nous dit que ChatGPT, à partir d’une séquence de mots, « donne une distribution de probabilité de ce que pourrait être le prochain mot ». Mais elle ne présume pas du mode de calcul de cette probabilité, ce qui évite une simplification qui, dans les citations précédentes, occulte un point absolument essentiel.
OUI, ChatGPT produit une distribution de probabilités de ce que pourrait être le prochain mot d’une séquence, comme le dit M. Phi.
MAIS attention, cette distribution de probabilités ne résulte pas directement d’une analyse statistique de séquences comportant ce mot dans le corpus d’apprentissage. Lors de son apprentissage, ChatGPT, comme toutes les IA basées sur les réseaux de neurones profonds, crée un modèle (techniquement, un instance de modèle) extrêmement complexe, dont personne à l’heure actuelle ne comprend comment il organise ses connaissances (Les IA de ce type sont le résultats de recherches essentiellement empiriques). Ce modèle est constitué de milliards de paramètres dont les valeurs ont été fixées lors de l’entraînement de l’IA. S’il est difficile de dire ce qu’est ce modèle, on peut en tout cas dire ce qu’il n’est pas : ce n’est pas une représentation littérale du corpus d’apprentissage, ce n’est pas le résultat d’un apprentissage par cœur de ce corpus, ce n’est pas un arbre de décision.
Ce modèle fait montre d’une remarquable capacité à généraliser ses données d’apprentissage pour résoudre des problèmes basés sur des données différentes de celles incluses dans le corpus d’apprentissage.
Certaines IA basées sur des réseaux de neurones profonds s’avèrent capables de faire des choses qu’on ne leur a pas apprises explicitement. Par exemple, on peut entrainer des IA à réparer des photos de chats ayant été dégradées, et ensuite non seulement leur faire réparer des photos de chats dont elles n’ont jamais vu l’original, mais aussi leur faire créer de toutes pièces, à partir d’images d’entrée représentant un bruit aléatoire, des chats parfaitement plausibles.
C’est ce qui semble se passer avec ChatGPT. Le jeu d’apprentissage est constitué de couples $(s,m)$ où $s$ est une séquence de mots dans un texte du corpus et $m$ le mot situé immédiatement après $s$. La fonction $p$ effectivement apprise associe à toute séquence $s$ du jeu d’apprentissage un vecteur de probabilité $p(s)$ dans lequel le mot qui suit la séquence $s$ a une probabilité 1 et tous les autres mots du corpus une probabilité 0.
Mais une fois entraîné, le système peut accepter en entrée tous les textes possibles et imaginables. Quand on l’interroge, on lui demande d’appliquer à notre question (suivie de la partie déjà produite de la réponse) une fonction de prédiction $P$ qui est une généralisation de la fonction $p$ que le Truc a effectivement appris à calculer lors de son entraînement. Le vecteur de sortie associé par la fonction $P$ à une séquence d’entrée ne faisant pas partie du jeu d’apprentissage ne sélectionne pas un unique mot avec une probabilité 1, mais attribue des probabilités à différents mots du corpus. C’est ce qui permet au Truc de donner des réponses différentes à une même question.
Aucune connaissance scientifique ne permet d’affirmer que les réponses produites sont « intelligentes » d’autant que ce terme est un mot fourre-tout aux contours flous, ayant une connotation anthropocentrique. Mais aucune base scientifique ne permet de présumer que cette fonction produit des séquences de mots sans aucune profondeur, ou des textes construits à partir de mots choisis de manière purement statistique, et encore moins de dire que ChatGPT est un perroquet stochastique. Il faut comprendre que la fonction de prédiction $P$ n’est pas calculée par une formule de statistique d’origine humaine, mais par une formule qui a émergé du processus d’apprentissage et qui ne peut être ni explicitée, ni comprise par des êtres humains. On ne peut donc pas prétendre qu’elle se limite à traduire des corrélations entre mots et séquences de mot.
L’hypothèse qui me parait la plus plausible au moment où j’écris ces lignes (susceptible d’être révisée car il faut être humble face à la complexité de ce qui se passe dans un réseau de neurones artificiels de grande taille) est que ChatGPT ne peut satisfaire les contraintes qui lui sont imposées lors de son apprentissage qu’en produisant un modèle de représentation et d’exploitation des connaissances qui capture, d’une certaine façon, non seulement les règles de grammaire de différents langages (naturels et informatiques), mais aussi certains éléments de la structure, de la logique, et de la sémantique sous-jacentes à de nombreux textes écrits dans ces langages. Ces méta-connaissances ne sont pas représentées explicitement. Elles sont intriquées dans la masse des paramètres des réseaux de neurones artificiels qui leur servent de support. Mais elles s’expriment lors de l’utilisation du système parce que leur décodage fait partie des capacités acquises lors de sa phase d’apprentissage.
Certains résultats obtenus avec ChatGPT me laissent penser que le modèle qui a émergé de son entraînement lui permet de transposer certains modes de raisonnements explicités dans son corpus d’apprentissage à des problèmes présentés avec des mots différents et des valeurs numériques différentes de celles exprimées dans ce corpus, mais aussi à combiner des savoir-faire issus de différentes sources du corpus. Voici un exemple :

Dans cet exercice, je détourne complètement le concept de groseille, qui devient un animal à trois pattes, tout en brouillant les pistes en parlant d’une planète sortie de mon imagination. Pourtant, ChatGPT réussi à résoudre le problème alors qu’on peut raisonnablement supposer que dans son corpus d’apprentissage, les groseilles n’ont pas de pattes et ne pèsent pas 500 grammes. Il y a une aspérité dans l’explication, plus précisément dans la deuxième phrase du raisonnement, où le mot « pèse » devrait être remplacé par « représente ». Par ailleurs, rien ne permet d’affirmer que le Truc a effectivement procédé de la manière dont il l’explique pour produire le résultat, mais la démarche décrite est cohérente et le résultat est exact.
Le point important est que la démarche de résolution de ce problème (comme celle permettant à l’engin d’en résoudre de nombreux autres) ne provient pas des algorithmes implémentés dans le système par ses concepteurs. Elle provient de documents appartement au corpus d’apprentissage et de rétroactions humaines réalisées lors de certaines phases de l’entraînement de ChatGPT.
Voilà ce qu’en a dit ChatGPT 4 lorsque je l’ai interrogé à ce sujet après m’être forgé cette opinion et avoir écrit ce qui précède. Quand mien même, en toute hypothèse, ce texte refléterait plus l’avis des personnes ayant créé ChatGPT que de l’engin lui-même, il ne serait pas à prendre à la légère.

Le but ici n’est pas de multiplier les exemples. Il est toujours possible d’en trouver, même assez facilement, qui donnent des résultats faux, voire incohérents. Le modèle sous-jacent à ChatGPT ne permet en aucun cas de capturer toutes les informations contenues dans son corpus d’apprentissage, et la nature même du mode de représentation des connaissances utilisé ne donne aucune garantie de fiabilité, cohérence et exactitude des productions de l’engin.
Il existe par ailleurs des limites théoriques des capacités d’inférences, donc de déduction, du Truc. Ces limites sont liées à la notion d’irréductibilité algorithmique, comme le mentionne Stephen Wolfram dans ce billet.
Mais je ne peux pas, en toute conscience, affirmer que ChatGPT ne comprend rien à ce qu’il écrit. Je pense, au contraire, que l’engin peut faire preuve, dans certains contextes, d’une forme de compréhension qui lui permet de produire des résultats cohérents lorsqu’on lui demande de traiter des problèmes présentant certaines différences avec ceux figurant dans son corpus d’apprentissage.
Je pense qu’il faudra beaucoup de temps et de recul pour cerner les capacités et les limites des IA génératives telles que ChatGPT. Mais si l’intelligence de ces systèmes peut être discutée, on ne peut nier que ChatGPT a certaines compétences, qu’il convient d’évaluer au cas par cas, sans apriori, dans ses différents domaines d’application.
J’enseigne la programmation et l’algorithmique depuis 30 ans à des niveaux allant de bac+1 à bac+5 et j’estime que l’engin a des compétences de bon niveau troisième année de licence d’informatique universitaire. Concrètement, il est capable de traiter des exercices originaux présentés de la même manière que dans mes sujets d’examens et de donner, souvent, des réponses correctes et remarquablement bien expliquées.