J’ai désactivé les commentaires pour éviter les spams et les problèmes de RGPD, mais je suis sur twitter @OlivierBailleux.
Article mis en avant
J’ai désactivé les commentaires pour éviter les spams et les problèmes de RGPD, mais je suis sur twitter @OlivierBailleux.

Les billets les plus récents sont accessibles ici.

Au moment où les Intelligences Artificielles deviennent de plus en plus performantes et (grâce a un apprentissage implicite, sans utiliser de routines ni d’automatismes pré-câblées ou programmées lors de leur conception) parviennent à surpasser des personnes humaines dans de nombreuses tâches complexes, il me parait essentiel que les personnes humaines ne se retrouvent pas confinées à des rôles purement routiniers, mais qu’elles continuent à s’épanouir et à innover en développant autant que possible leur pensée critique, leur esprit scientifique, et leur autonomie d’apprentissage.
C’est pourquoi je suis très inquiet de voir, dans certains programmes d’enseignement, notamment en mathématiques, beaucoup de tâches complexes purement scolaires élevées au rang d’automatismes à acquérir.
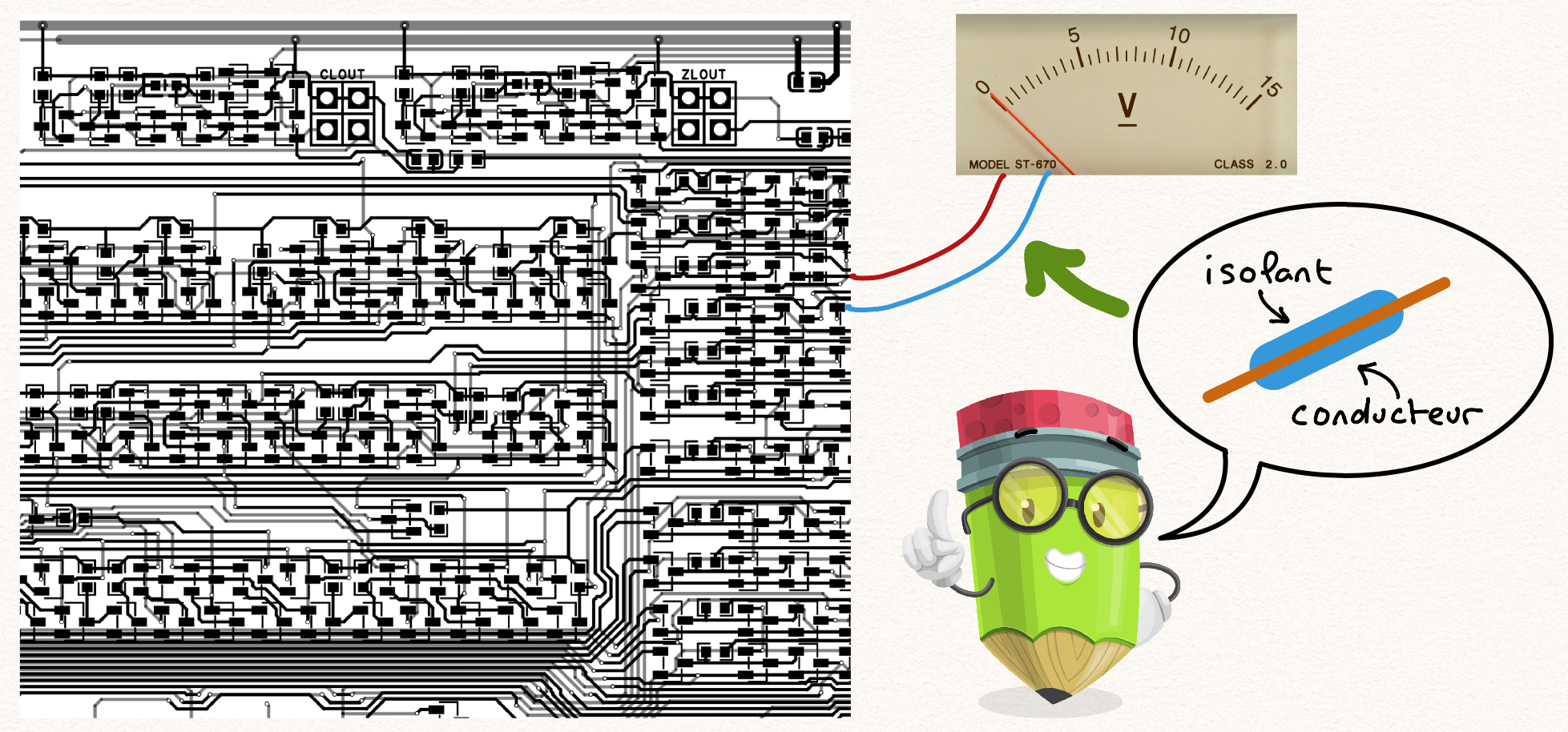
De nombreuses publications de vulgarisation mettent l’accent sur le fait que le principe de ChatGPT repose sur la prédiction du mot suivant le plus probable d’une suite de mots donnée. C’est un peu comme dire que le principe de fonctionnement d’une voiture est de faire tourner les roues à l’aide d’un moteur. La vraie question, au delà de « comment fonctionne le moteur ? », est « pourquoi le moteur fonctionne-t-il ? »

L’application ChatGPT réussi à réaliser des tâches qui, lorsqu’elle sont faites par des humains, nécessitent une compréhension en profondeur, non seulement des énoncés décrivant les objectifs à atteindre, mais aussi de certains concepts et principes à utiliser pour atteindre ces objectifs.
Continuer la lecture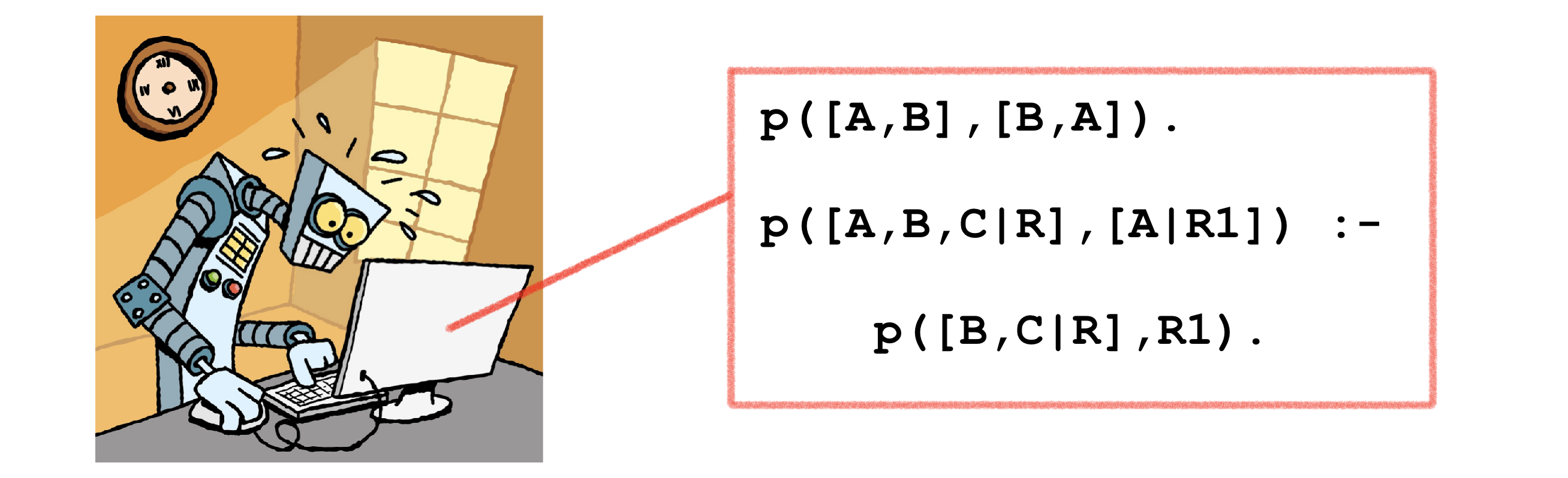
Prolog et ChatGPT sont des outils relevant de deux champs de l’intelligence artificielle : l’IA basée sur l’automatisation du raisonnement et celle basée sur des réseaux de neurones profonds. Il est très difficile de leur trouver des points communs, si ce n’est l’intention initiale de permettre le traitement du langage naturel, mais avec des approches complètement différentes.
Les possibilités des deux engins sont on ne peut plus différentes, mais m’ont complètement stupéfié au moment où j’en ai eu connaissance à 35 ans d’intervalle.
Continuer la lectureEn classe, résigné à passer des journées entières dans un environnement très normatif, je pensais souvent aux vertes vallées de ma campagne. C’était hors des murs de l’école, où tant de choses devenaient plus passionnantes et attrayantes, que ma soif d’apprendre était la plus forte.
Sans connaître le mot, j’ai réalisé un jour qu’une grande partie des plus de 10000 heures que j’ai passées dans des établissements d’enseignement avant le bac relevaient du présentéisme. Pendant ces moments interminables de présence imposée, je ne percevais qu’un vague écho de ce que disaient les enseignantes et enseignants et mon esprit vagabondait.

Je vois passer sur Twitter et sur certains sites WEB des billets qui présentent l’efficacité de la pédagogie de la découverte comme un mythe et préconisent de l’abandonner complètement au profit d’une approche pédagogique plus explicite, voire d’une méthode appelée « enseignement explicite » dont l’efficacité est démontrée par des données probantes.
Au cours de ma scolarité et de mes études supérieures, j’ai été confronté aux deux approches, souvent utilisées conjointement. Je relate ici quatre situations vécues montrant certains avantages et inconvénients d’un enseignement implicite et d’un enseignement explicite.

Ce que je vais dire ici à propos des mathématiques correspond à l’état actuel de ma compréhension des fondements de ce domaine, et résulte de centaines d’heures de réflexion réparties tout au long de ma vie. Ma compréhension évolue en permanence. Si vous êtes mathématicienne ou mathématicien et que certains de mes propos vous paraissent erronés, merci de me le signaler, par exemple en m’écrivant à olivier point bailleux at u tiret bourgogne point fr.
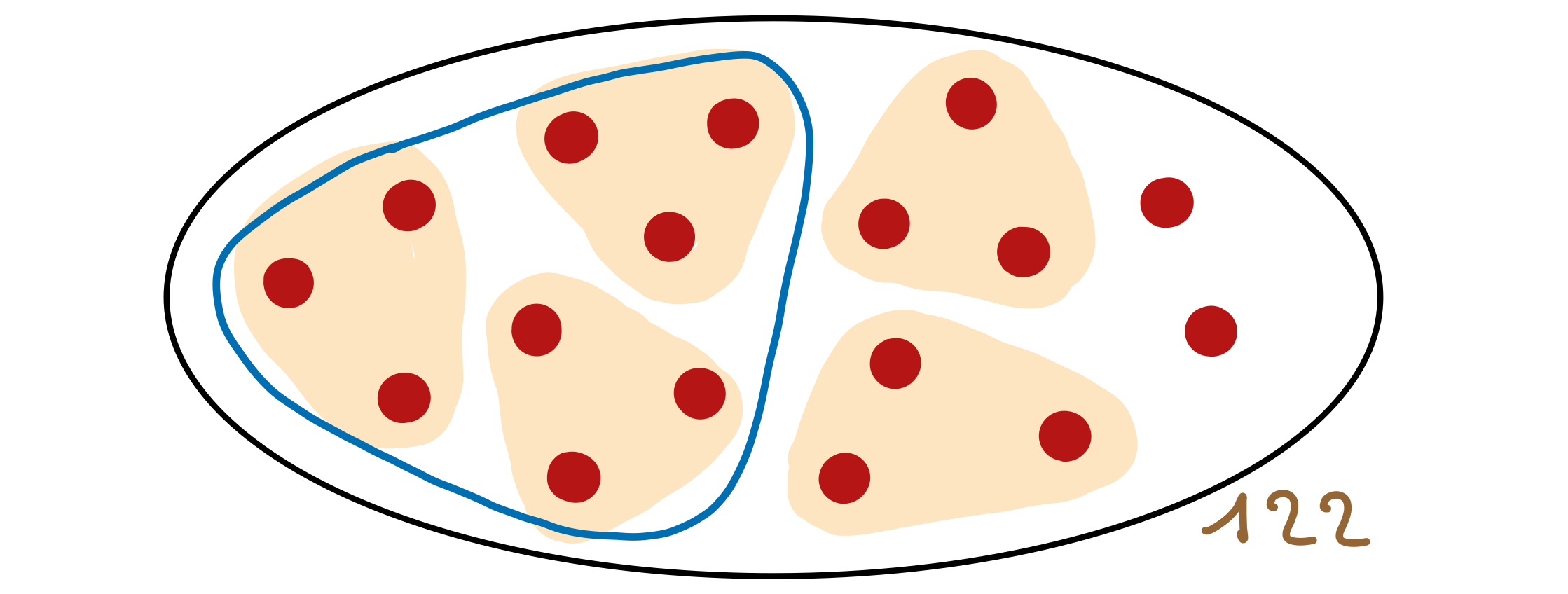
Un des objectifs des sciences de l’éducation est de proposer des méthodes ou approches pédagogiques permettant d’améliorer l’efficacité des apprentissages, et de valider ces méthodes par des données probantes issues d’expérimentations à suffisamment grande échelle.

La plupart des systèmes éducatifs organisent les enseignements en présence, au sein de classes, souvent constituées de personnes du même âge, devant acquérir les mêmes savoirs à même échéance. L’efficacité d’une approche pédagogique se mesure généralement par le taux de réussite, c’est à dire la proportion des élèves ayant atteint les objectifs d’apprentissage au terme de la période d’enseignement.
Continuer la lectureAutoriser les étudiantes et étudiants à ne pas participer à tous les TD en présence, leur permettre de les remplacer par des activités en autonomie, c’est commettre une sorte de sacrilège dans un univers où l’assiduité aux enseignements en présence est considéré comme un facteur primordial de réussite.
